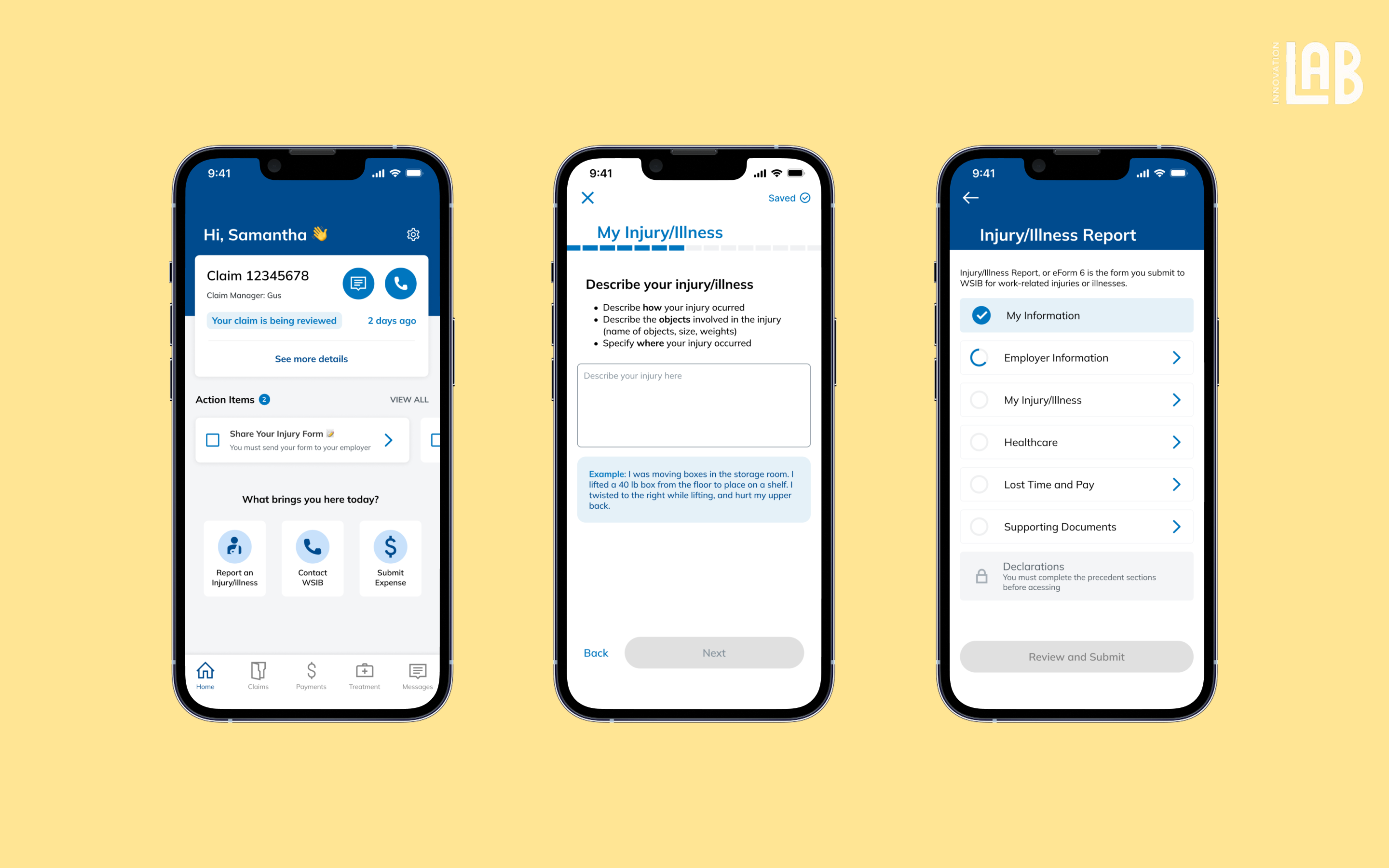
Mobile, App, Insurance
WSIB Mobile App for Claim Tracking
Take a peek

YEAR
ROLE
Company
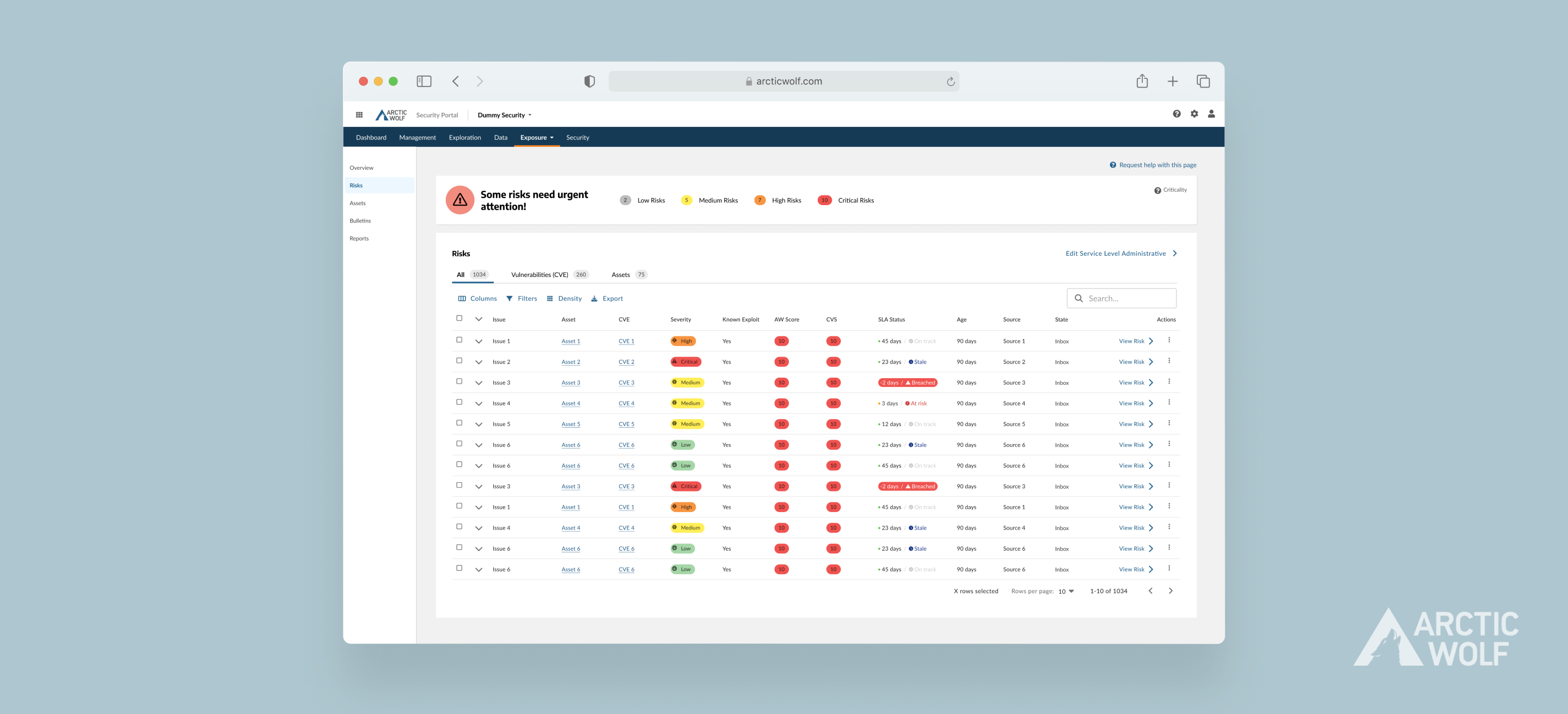
Data showed declining resolution of low-severity risks, which accumulated into urgent last-minute tasks. I recommended modifying SLA status indicators first, leveraging their association with urgency to drive action.
I interviewed Information Architecture Engineers and Cybersecurity Analysts to gain a simplified understanding of the triage process—how risks are characterized and information is entered into the table. They expressed a preference for more quantitative labels, which provide specific and clearer direction.
The current dashboard clearly has an overwhelming amount of color that lacks hierarchy and may not meet accessibility standards. This led me to restructure the color coding and iconography for each severity level and propose a design system change. For starters, it was best not to rely on color alone.
[insert image of dashboard]
Thanks for stopping by! Please come back soon~


© Made by Yan through countless solo jamming sessions